Read Review
Read Review

Introducción
Bienvenidos a nuestro nuevo artículo, donde exploraremos las emocionantes actualizaciones de Chia DataLayer. Hoy, nos adentraremos en la recién lanzada integración con plugins, una innovación caliente y reciente del equipo de desarrollo de Chia.
Como se ha hecho saber muy recientemente, Chia ha estrenado una nueva funcionalidad que permite desarrollar una capa lógica adicional a DataLayer que permite desarrollar plugins en Python de cara a sincronizar datos entre Chia DL y otras fuentes de datos más tradicionales para facilitar el robustecimiento y la disponibilidad de de dichos datos, o bien para darle el uso que el usuario considere necesario.
El primer plugin desarrollado por el equipo de Chia nos permite utilizar Amazon S3 como almacenamiento adicional para nuestros datastores de DataLayer.
Esta sinergia entre la nube y DL resulta muy beneficiosa en términos de eficiencia operativa y reducción de costos ya que es posible ajustar los recursos de la nube según la demanda sin tener que invertir en infraestructura física costosa.
Amazon S3
El primer plugin que ha desarrollado el Core Team de Chia se trata de una integración con buckets de Amazon S3, que nos permite trabajar con datos entre ambas tecnologías tanto en un modelo push como pull, es decir, que podemos usar un bucket de S3 para descargar datos hacia DL o bien usarlo al contrario para subir datos desde DL hacia S3.
Esto nos permite tener de forma sencilla una réplica administrada de nuestro repositorio de Datalayer, con las todas las ventajas que nos ofrece tenerlo en una cloud.
Estructura de datos de un bucket de S3
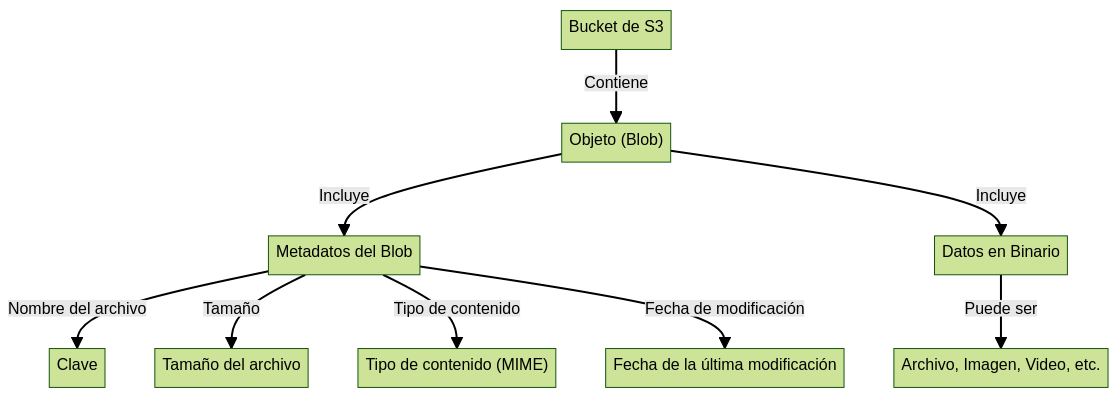
El diagrama ilustra la estructura y componentes de un objeto almacenado en un bucket de Amazon S3. Partes del diagrama:
- Bucket de S3: En la parte superior del diagrama, tenemos el Bucket de S3. Un bucket es como un contenedor en Amazon S3 donde los datos se almacenan en forma de objetos. Los buckets son útiles para organizar el almacenamiento y controlar el acceso a los datos.
- Objeto (Blob): Dentro del bucket, encontramos un Objeto, también conocido como Blob. Los objetos son las unidades fundamentales de almacenamiento en Amazon S3. Cada objeto consiste en datos y un conjunto de metadatos que describe el objeto.
- Metadatos del Blob: Los metadatos están asociados con el objeto y son un conjunto de información adicional sobre el objeto. Los metadatos incluyen:
- Clave: La clave es el nombre del archivo del objeto y es única para cada objeto dentro de un bucket. Se utiliza para acceder al objeto en Amazon S3.
- Tamaño del archivo: Los metadatos incluyen información sobre el tamaño del archivo del objeto.
- Tipo de contenido (MIME): Los metadatos también contienen el tipo de contenido del objeto, que especifica el formato de los datos.
- Fecha de la última modificación: Los metadatos contienen la fecha en que el objeto fue modificado por última vez.
- Datos en Binario: Los datos del objeto están almacenados en formato binario. Los datos pueden ser cualquier tipo de contenido.
Chia DataLayer
Estructura de datos de un datastore de Chia DataLayer

El diagrama proporciona una visión esquemática de cómo funciona un Datastore dentro de Chia DataLayer, aquí se detallan los componentes que se presentan en el diagrama:
- Datastore de DataLayer: Al inicio del diagrama, se encuentra el Datastore de DataLayer. Un Datastore actúa como un repositorio para almacenar información en forma de pares de clave y valor.
- Clave / Valor: Dentro del Datastore, los datos se almacenan como pares de clave y valor. Cada elemento almacenado tiene una clave única que se utiliza para acceder y recuperar el valor asociado.

- Datos en Hexadecimal: Los valores almacenados están en formato hexadecimal. Esto significa que los datos se representan usando un sistema de numeración de base 16 que incluye los números del 0 al 9 y las letras de la A a la F.
- Archivo, Imagen, Video, etc.: Los datos en hexadecimal pueden representar diversos tipos de contenido, como archivos, imágenes, videos, y más.
- Ficheros .dat (Filesystem): El contenido, como archivos, imágenes, videos, etc., se almacena en ficheros con extensión .dat dentro del sistema de archivos. Los archivos .dat son contenedores de datos binarios y se utilizan para almacenar información.
Puesta en común

- Contenedores de Datos: Tanto Amazon S3 como Chia DataLayer actúan como contenedores para almacenar datos. Amazon S3 utiliza "Buckets" mientras que Chia DataLayer utiliza "Datastores".
- Estructura de Almacenamiento: En ambos sistemas, los datos se almacenan en una forma estructurada. Amazon S3 almacena datos en forma de "Objetos (Blobs)", mientras que Chia DataLayer almacena datos en pares de "Clave / Valor" aunque finalmente terminan en ficheros .DAT a nivel de filesystem, esto sugiere que ambos sistemas permiten organizar y almacenar datos de manera estructurada.
- Los ficheros .DAT Son los que se almacenarán dentro de los blobs de S3.
Requisitos para utilizar Amazon S3 como réplica de un repositorio de DataLayer
- Crear / reutilizar un usuario de IAM de AWS
- Proporcionarle el nivel de permisos necesarios para poder interactuar con los buckets de S3
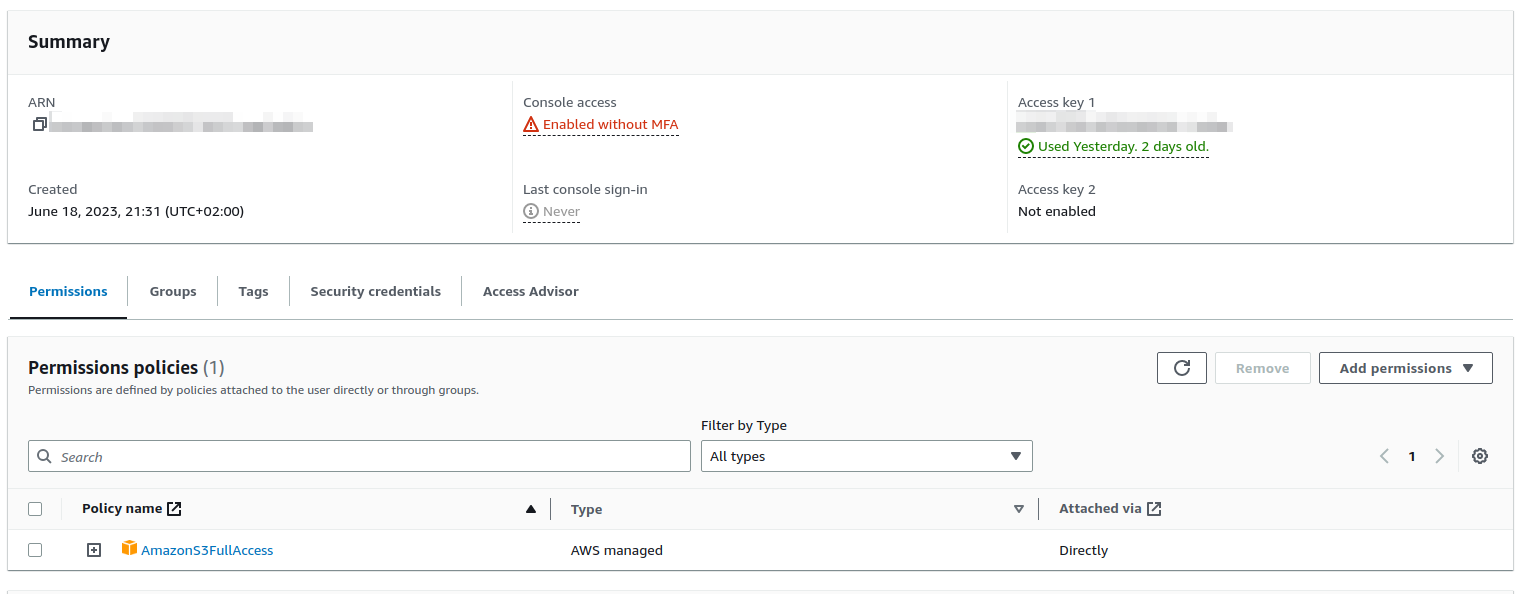
3. Crear un Access Key y apuntar los tokens para poder usarlos a posteriori cuando se configure el plugin
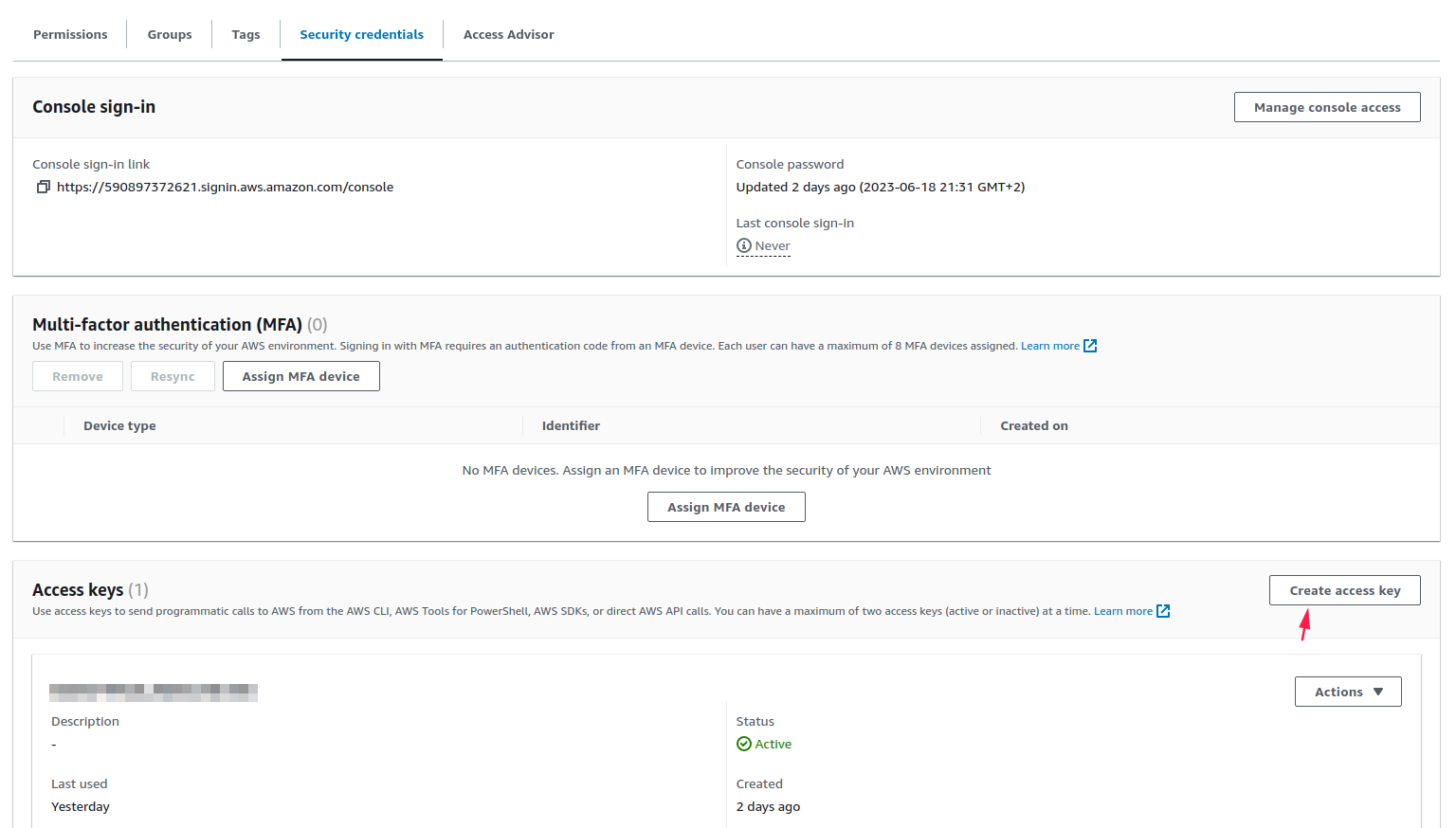
4. Ir a la interfaz de Amazon S3 y crear un Bucket vacío (en mi caso lo he llamado test-datalayer)

Identificar las dependencias
- Ubicarse en el directorio ./chia/data_layer de una instalación oficial de chia-blockchain.
- Localizar los siguientes ficheros:
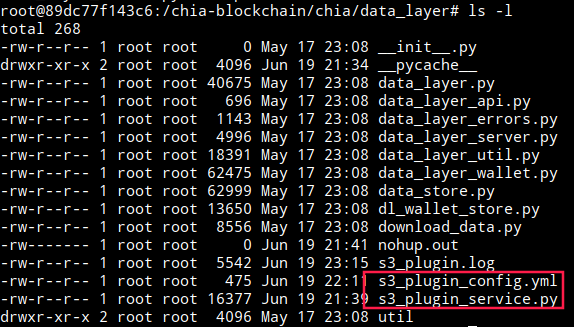
3. s3_plugin_config.yml: Es el archivo de configuración donde se indican los parámetros para configurar el plugin, además de los secretos para autenticarse con Amazon S3.
4. s3_plugin_service.py: Es el script del plugin que interactúa con S3 y DataLayer, leyendo los datos del archivo de configuración s3_plugin_config.yml.
Preparar la configuración
Editar el fichero s3_plugin_config.yml y adaptarlo según necesidad. El siguiente ejemplo se utilizará para subir archivos desde un datastore de DL existente hacia el bucket de Amazon S3 creado previamente.

# Este es el comienzo de un bloque llamado "instance-1", que agrupa una configuración específica para una instancia.
instance-1:
# Define el nombre del archivo en el que se guardarán los registros (logs).
log_filename: "s3_plugin.log"
# Define el nivel de logging
log_level: DEBUG
# Especifica la ruta en el sistema de archivos donde se ubicarán los archivos DAT del servidor.
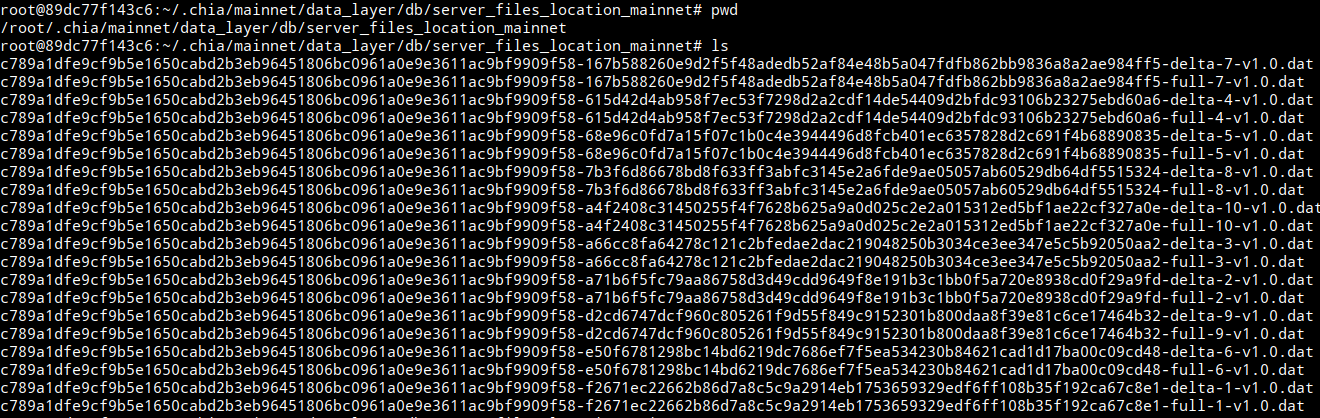
server_files_location: "/root/.chia/mainnet/data_layer/db/server_files_location_mainnet"
# Define el puerto en el que se ejecutará el servicio o la aplicación.
port: 8998
# Credenciales con privilegios para acceder al servicio de AWS S3
aws_credentials:
# ID de la clave de acceso para autenticarse en AWS.
access_key_id: "xxxxxxxxx"
# Clave de acceso secreta para autenticarse en AWS.
secret_access_key: "xxxxxxxxxxx"
# Región de AWS a la que se quiere conectar.
region: "eu-west-3"
# Bloque que contiene la configuración para trabajar con un datastore de DataLayer.
# Si se indica un valor en upload_bucket, los archivos .DAT del datastore indicado abajo en la key store_id se subirán a ese bucket.
# Si se indica un bucket de S3 en download_urls, descargará los archivos desde uno de esos orígenes. Debe contener el esquema de s3. Ejemplo:
# download_urls: ["s3://cripsis-xyz-1", "s3://cripsis-xyz-2"]
# Este es un elemento en una lista. Puede contener var
# Identificador único del almacenamiento.
stores:
- store_id: "c789a1dfe9cf9b5e1650cabd2b3eb96451806bc0961a0e9e3611ac9bf9909f58"
# Especifica el nombre del bucket en AWS S3 al cual se subirán archivos.
upload_bucket: "test-datalayer"
# Es una lista de URLs desde donde se pueden descargar archivos. Está vacía en este ejemplo.
download_urls: []Arrancar la instancia
Procedemos a arrancar la instancia instance-1 que hemos definido dentro de nuestro archivo de configuración con el siguiente comando:
python3 s3_plugin_service.py instance-1
chia data create_data_storeComo podemos observar, se debe de especificar el identificador de la instancia como primer parámetro del script

Ahora que sabemos que se ha arrancado y sin errores, procedemos a ejecutarlo en segundo plano con nohup:

nohup python3 s3_plugin_service.py instance-1 &Comenzar la subida
- Atendiendo a la API Rest de Chia, podemos subir iniciar la subida de los archivos con la siguiente petición HTTP con curl:
curl -X POST -d '{"store_id": "c789a1dfe9cf9b5e1650cabd2b3eb96451806bc0961a0e9e3611ac9bf9909f58"}' http://127.0.0.1:8998/handle_upload- Modificar store_id con el ID del datastore deseado.

- Verificar que la respuesta es true.
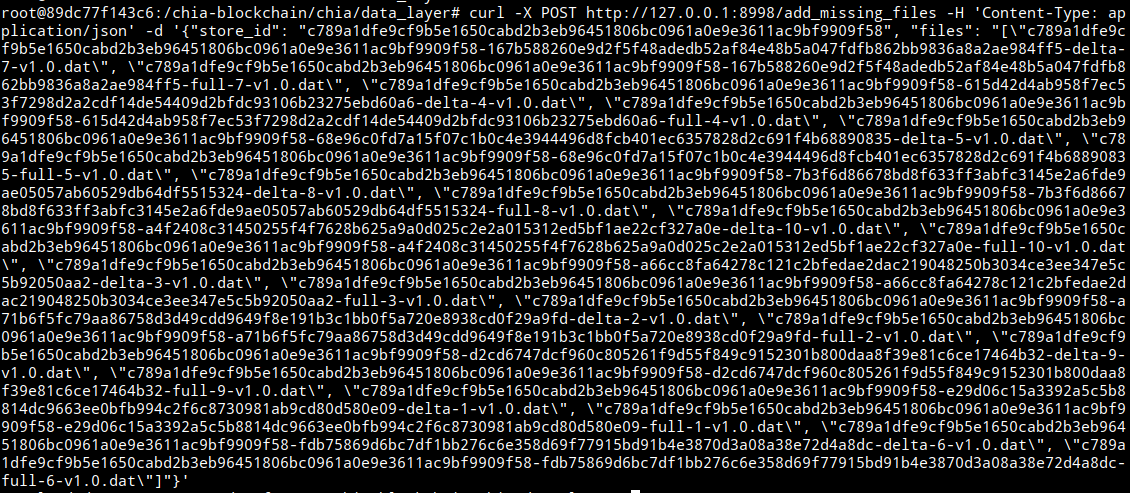
curl -X POST http://127.0.0.1:8998/add_missing_files -H 'Content-Type: application/json' -d '{"store_id": "c789a1dfe9cf9b5e1650cabd2b3eb96451806bc0961a0e9e3611ac9bf9909f58", "files": "[\"c789a1dfe9cf9b5e1650cabd2b3eb96451806bc0961a0e9e3611ac9bf9909f58-167b588260e9d2f5f48adedb52af84e48b5a047fdfb862bb9836a8a2ae984ff5-delta-7-v1.0.dat\", \"etc.dat\"]"}'Los nuevos archivos que se vayan generando deberían de subirse tras volver a ejecutar el commando handle_upload visto anteriormente.
Verificar los datos en S3
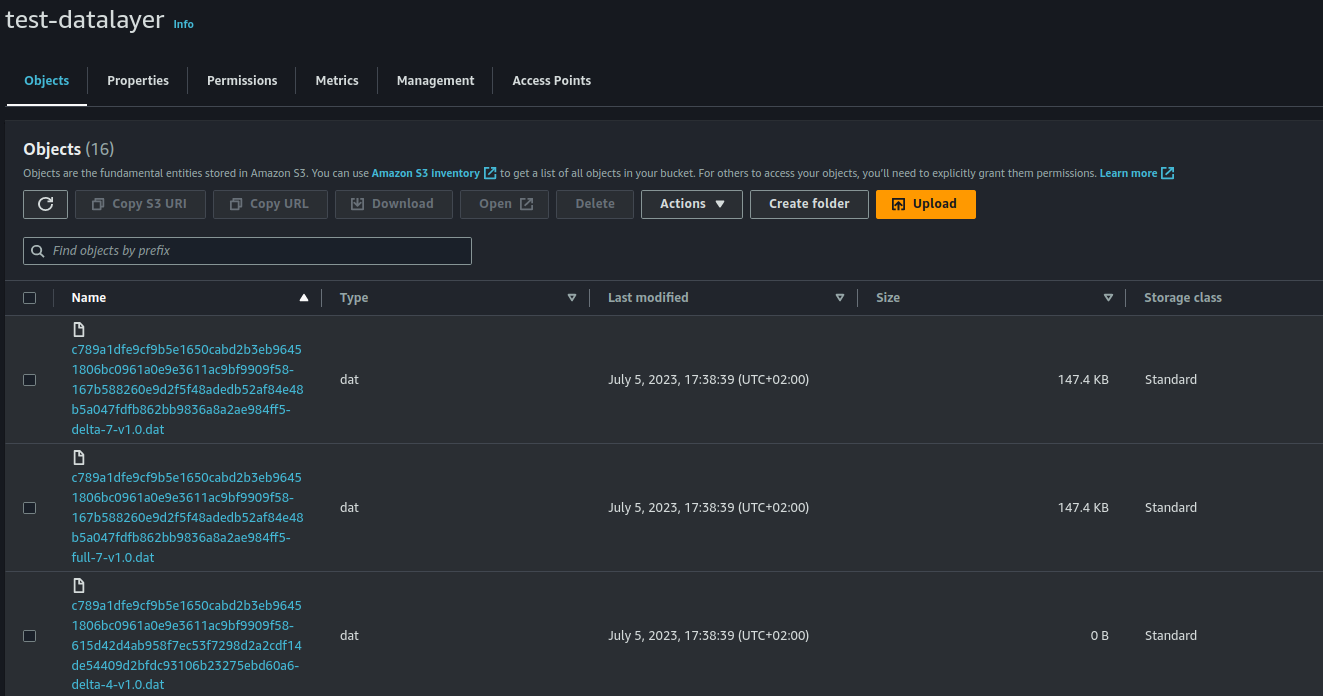
Podemos ver que los datos ya se han subido de forma correcta!
Crear y compartir contenido de calidad requiere tiempo y esfuerzo. Si aprecias mi trabajo y te gustaría ver más de él, considera hacer una pequeña donación.
Cada contribución, por pequeña que sea, hace una gran diferencia y me ayuda a continuar con este trabajo que tanto disfruto.
Si tienes cualquier tipo de sugerencia o quisieras que hablara de algún tema en concreto, ¡házmelo saber!