 Read Review
Read Review

Introducción a la observabilidad
En la vanguardia tecnológica actual, los complejos sistemas digitalizados detrás de cada negocio demandan herramientas robustas de observabilidad. Si uno o varios procesos clave dentro de tu entidad está digitalizado en alguno de sus puntos, significa que ya está orientado hacia la madurez digital y comienza a adoptar un enfoque data-driven (impulsado o orientado por datos). La cuestión es: ¿Cuenta la organización con los mecanismos y herramientas necesarias para conocer con exactitud cómo se desempeñan dichos procesos de negocio?
En este artículo, veremos cómo la observabilidad (o en inglés observability), siendo un concepto amplio y multifacético, puede derivar en varias prácticas y herramientas especializadas para cubrir un amplio abanico de casos de uso; a día de hoy se erige como fundamental para asegurar la continuidad operativa y fomentar una mejora continua de los negocios digitales modernos y su objetivo es obtener una comprensión profunda del estado interno de los sistemas a través de los datos que generan.
Cada departamento dentro del negocio es fundamental para su correcto funcionamiento; Ventas y Marketing, Producción y Operaciones, Finanzas, Gestión de la Cadena de Suministro, Atención al Cliente, Tecnología de la Información (TI), etc… Aunque probablemente no cuentes con todos o te falten algunos, seguro que puedes conseguir mucho más de ellos.
¿Conoces realmente cómo se desempeñan? ¿Cuál es su rendimiento? ¿Dónde se encuentran los cuellos de botella más comunes? ¿Qué impacto económico están infligiendo? ¿Qué incidencias están experimentando? ¿Cómo anticiparse a ellas?
La observabilidad, como disciplina dentro del campo IT, viene a ayudarte a responder a todas estas preguntas.
Fundamentos de la Observabilidad
Definición y Concepto
En términos generales, se puede definir como la habilidad de deducir el estado interno de un sistema a partir exclusivamente de sus salidas externas. En el ámbito del software, esto se traduce en la capacidad de discernir el funcionamiento y comportamiento de un sistema monolítico o distribuído mediante la información que él mismo revela; esto implica que, si se conocen las salidas durante un período de tiempo suficiente y entendemos cómo el sistema responde a las entradas, es posible inferir o reconstruir todos los estados internos posibles del sistema.
Su impacto en el negocio
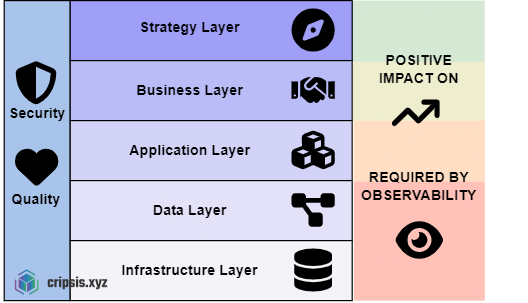
La observabilidad no es solo una herramienta técnica; es un facilitador estratégico que impacta profundamente en varios aspectos del negocio y es por eso que es clave en un proceso de transformación digital. La observabilidad comienza en la capa de infraestructura de los recursos de la organización, empezando a extraer datos (métricas, logs) de dichos recursos hardware, hasta llegar a la capa de aplicación de la cual también se extraerán trazas.
A continuación, se detallan los principales beneficios y cómo estos se traducen en ventajas competitivas tangibles:
Mejora en la Continuidad Operativa
La observabilidad permite identificar y resolver problemas antes de que se conviertan en incidentes críticos. Al tener una visibilidad clara y en tiempo real de los sistemas, las empresas pueden minimizar el tiempo de inactividad y asegurar la continuidad operativa. Esto es crucial para mantener la confianza del cliente y evitar pérdidas económicas significativas.
Optimización del Rendimiento
Con herramientas de observabilidad, es posible monitorear y analizar continuamente el rendimiento de las aplicaciones y los procesos. Esto facilita la detección de cuellos de botella y áreas ineficientes, permitiendo ajustes y mejoras que optimizan el uso de recursos y mejoran la eficiencia operativa.
Reducción de Costos
La capacidad de identificar problemas rápidamente y optimizar los recursos contribuye a una reducción significativa de costos operativos. Menos interrupciones y una mejor asignación de recursos tecnológicos y humanos resultan en ahorros que pueden reinvertirse en otras áreas del negocio.
Aumento de la Satisfacción del Cliente
Un sistema altamente observable puede asegurar un mejor rendimiento y disponibilidad de los servicios, lo que se traduce en una experiencia de cliente más positiva. La capacidad de resolver problemas rápidamente y mantener una operación fluida aumenta la satisfacción y lealtad del cliente.
Mejora en la Toma de Decisiones
La observabilidad proporciona datos valiosos y accionables que informan las decisiones estratégicas. Los líderes empresariales pueden basar sus decisiones en información precisa sobre el rendimiento y el estado de los sistemas, mejorando la planificación y ejecución de estrategias.
Fomento de la Innovación
Con una visión clara del funcionamiento interno de los sistemas, los equipos de desarrollo y operaciones pueden experimentar y probar nuevas ideas con mayor confianza. La rápida identificación y resolución de problemas permite un ciclo de desarrollo más ágil y una innovación continua.
Cumplimiento y Seguridad
La observabilidad también juega un papel crítico en el cumplimiento normativo y la seguridad. Permite un monitoreo detallado de las actividades y accesos dentro del sistema, ayudando a detectar y responder rápidamente a posibles amenazas de seguridad y garantizar el cumplimiento de las regulaciones.
Evolución desde la Supervisión Tradicional
Muchas veces se escucha que la observabilidad es una evolución significativa de la supervisión o monitorización tradicional en varios aspectos clave y es el caso. Herramientas como Nagios, Icinga, Pandora FMS, y un largo etc… han sido clave en la historia moderna y el sustento y correcto diagnóstico de las incidencias en el mundo IT. Esto no significa que la observabilidad sustituye directamente a la monitorización tradicional, sino que viene a completarla y hace parte de ella; se podría incluso decir que es la primera fase dentro de su implementación.
Aquí están los detalles de cómo la observabilidad se construye y expande sobre la base de la monitorización tradicional:
Amplitud y Profundidad de Datos
Monitorización Tradicional
Se centra principalmente en indicadores preestablecidos y métricas de salud del sistema, como CPU, memoria, y tiempos de respuesta.
Recolecta datos basados en umbrales conocidos para activar alertas.
Observabilidad
Recopila no solo métricas, sino también trazas y logs exhaustivos que proporcionan una visión detallada de todas las operaciones del sistema.
Permite el análisis retrospectivo para entender por qué ocurrieron ciertos comportamientos, no solo cuándo se desviaron de la norma.
Interrogabilidad y Diagnósticos
Monitorización Tradicional
- Ofrece una visión limitada y a menudo reactiva, adecuada para problemas conocidos y definidos previamente.
- Limitada en capacidad para explorar o investigar problemas sin definiciones previas de qué buscar.
Observabilidad
- Diseñada para permitir a los operadores hacer preguntas ad-hoc sobre el comportamiento del sistema, incluso preguntas que no se habían considerado antes de que surgiera un problema.
- Facilita una comprensión profunda del "cómo" y "por qué" detrás de los estados del sistema, no solo el "qué".
Enfoque en la Experiencia del Usuario
Monitorización Tradicional
Principalmente orientada a asegurar que los sistemas funcionen dentro de los parámetros operativos.
- Menos enfoque en cómo las interacciones específicas del usuario afectan o se ven afectadas por la infraestructura subyacente.
Observabilidad
- Incluye un fuerte enfoque en la experiencia del usuario final, evaluando el rendimiento del sistema desde la perspectiva del usuario a través de monitorización end-to-end y trazas distribuidas.
- Identifica cómo las falencias en el sistema afectan las transacciones y flujos de usuario reales.
Uso de Tecnología Avanzada
Monitorización Tradicional
Depende en gran medida de herramientas estáticas con poco aprendizaje o adaptación automática.
- Requiere configuración y ajustes manuales frecuentes.
Observabilidad
- Emplea técnicas avanzadas como inteligencia artificial y machine learning para análisis predictivo y detección de anomalías.
- Se adapta continuamente a cambios en el entorno del sistema, mejorando la detección y la respuesta a incidentes.
Escalabilidad y Dinamismo
Monitorización Tradicional
A menudo se enfrenta a dificultades para escalar o adaptarse a sistemas grandes y distribuidos.
- Puede ser ineficaz en entornos dinámicos o de rápida evolución.
Observabilidad
- Ideal para entornos de microservicios y arquitecturas distribuidas, donde los componentes pueden cambiar o escalar dinámicamente.
- Proporciona herramientas para sincronizar y correlacionar datos a través de una variedad de fuentes y servicios.
En conjunto, la observabilidad no solo mejora la monitorización tradicional sino que redefine la gestión de sistemas al proporcionar herramientas y técnicas más sofisticadas, adecuadas para el panorama tecnológico actual, complejo y en constante cambio.
Los 3 pilares fundamentales de la observabilidad

A nivel técnico, se fundamenta en tres pilares principales: logs, métricas y trazas. Cada uno de estos elementos proporciona una visión única y complementaria del comportamiento del sistema, facilitando una comprensión integral de su estado y rendimiento.
Logs
Los logs son registros detallados de eventos que ocurren dentro de un sistema. Se generan automáticamente por aplicaciones, servicios y componentes de infraestructura, y son esenciales para el diagnóstico de problemas y el análisis post-mortem. Los logs pueden ser de varios tipos, como logs de errores, de acceso, de auditoría, entre otros.
Ejemplo:
Supongamos que tenemos una aplicación web que gestiona pedidos en línea. Si un usuario intenta realizar un pedido y la operación falla, el log podría contener una entrada como esta:
2024-05-20 14:35:22 ERROR PedidoService - Error al procesar el pedido #12345: Conexión con la base de datos fallida.Este registro proporciona información crucial sobre el momento y la naturaleza del error, ayudando a los desarrolladores a identificar y solucionar el problema.
Metrics
Las metrics son datos cuantitativos que representan el rendimiento y el estado de diferentes componentes del sistema. Se recopilan y almacenan a intervalos regulares, y permiten a los equipos de operaciones monitorear la salud del sistema y detectar anomalías en tiempo real.
Ejemplo:
Continuando con nuestro ejemplo de la aplicación de pedidos en línea, una métrica relevante podría ser el número de pedidos procesados por minuto. Si normalmente se procesan 100 pedidos por minuto, pero de repente esta cifra cae a 20, esto indica un posible problema que necesita ser investigado.
{
"timestamp": "2024-05-20T14:35:00Z",
"metric": "pedidos_procesados",
"value": 20
}Además, otras métricas como el uso de CPU, la latencia de las solicitudes y la memoria disponible también son cruciales para evaluar el rendimiento general del sistema.
Traces
Los traces proporcionan una visión detallada del recorrido de una solicitud a través de varios servicios y componentes de una arquitectura distribuida. Son esenciales para entender el flujo de las transacciones y para identificar cuellos de botella o fallos en la cadena de servicios.
Ejemplo:
Imaginemos que un usuario realiza un pedido en nuestra aplicación de pedidos en línea. Un trace podría mostrar cómo esta solicitud viaja desde el front-end al servicio de autenticación, luego al servicio de procesamiento de pedidos, y finalmente a la base de datos. Si hay una demora en el procesamiento del pedido, el trace puede revelar que el cuello de botella está en el servicio de autenticación, que tarda más de lo esperado en verificar al usuario.
TraceID: 5f3c1e2d9a3b
---
Inicio: 2024-05-20T14:35:22Z
Duración: 3.2s
Pasos:
1. Autenticación (0.8s)
2. Procesamiento de Pedido (2.0s)
3. Actualización de Base de Datos (0.4s)La Correlación entre Logs, Metrics y Traces
La verdadera potencia de la observabilidad radica en la capacidad de correlacionar logs, metrics y traces para obtener una visión holística del sistema. Mientras que los logs ofrecen un registro detallado de eventos y errores específicos, las metrics proporcionan una visión cuantitativa del rendimiento en tiempo real, y los traces revelan el recorrido y la latencia de las solicitudes a través de los servicios. La combinación de estos datos permite a los equipos de operaciones y desarrollo conectar puntos y entender el contexto completo de los problemas. Por ejemplo, un pico en la latencia de una métrica de solicitud puede correlacionarse con un error específico registrado en los logs, y el trace correspondiente puede identificar exactamente en qué parte del flujo de la aplicación ocurrió el retraso. Esta correlación no solo acelera la identificación y resolución de problemas, sino que también facilita la implementación de mejoras proactivas en la infraestructura y el código.
El stack de observabilidad
A día de hoy se pueden encontrar múltiples “stacks” o frameworks que nos facilitan la extracción, el procesamiento y la ingesta de información en lagos de datos estructurados. Esto permite implementar la observabilidad con integraciones ya existentes para muchas tecnologías y de forma más sencilla que tener que desarrollar manualmente “conectores” para cada aplicación. Sin embargo, una vez obtenidos los datos suele ser necesario moldearlos o bien cruzarlos con otros datos, añadir información, quitarla, etc.. todo eso se consigue con herramientas de manipulación de datos que suelen ofrecer los propios stacks de Observabilidad. Suelen ser un conjunto de herramientas y tecnologías que permiten monitorear, analizar y gestionar el estado de los sistemas digitales, proporcionando visibilidad completa y en tiempo real del rendimiento, disponibilidad y comportamiento de las aplicaciones y la infraestructura.
Su estructura
Actualmente los stacks de observabilidad modernos suelen contar con los siguientes elementos o funcionalidades:
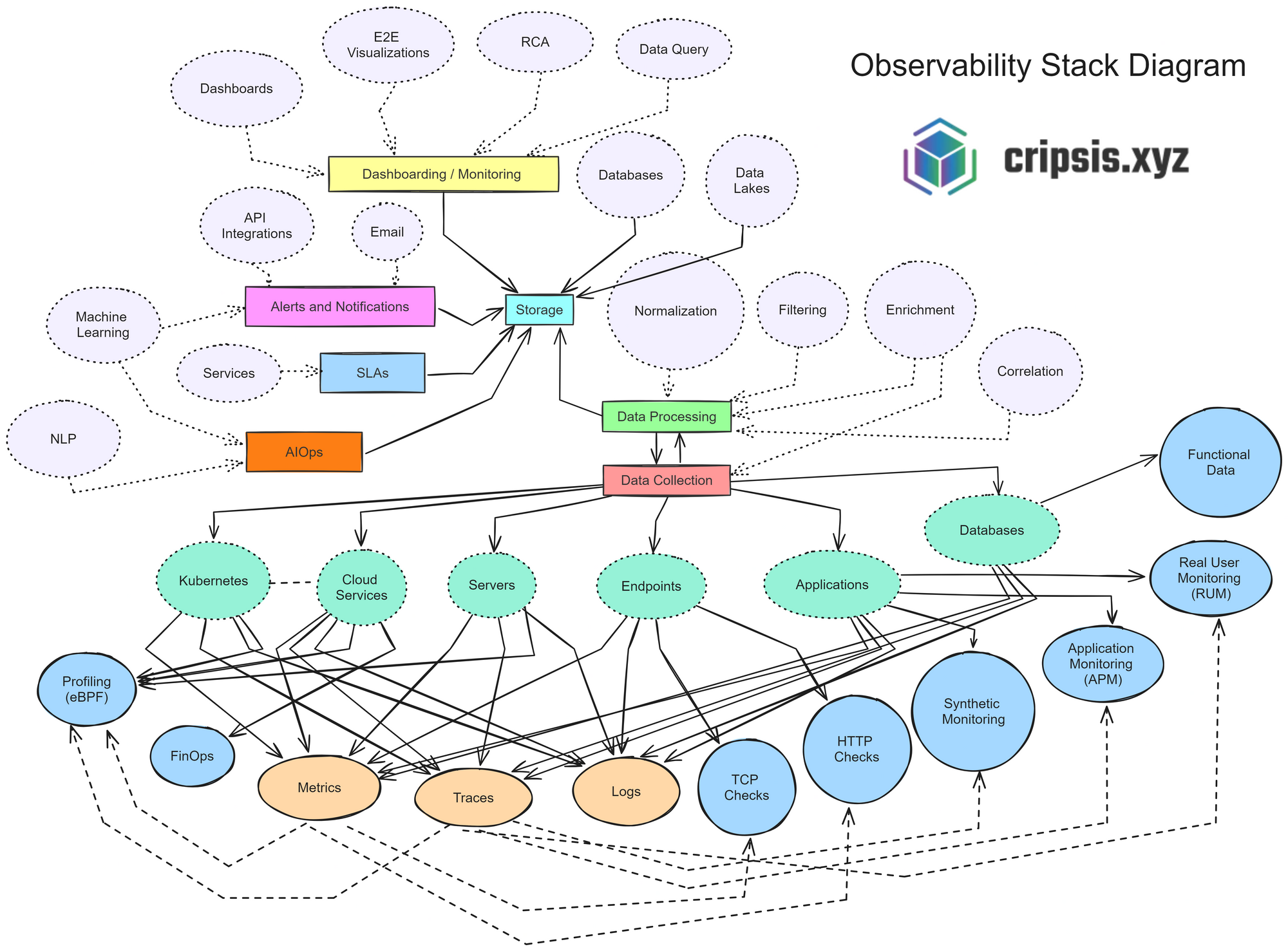
Dashboarding y Monitoreo
La observabilidad permite la capacidad de visualizar y monitorizar datos de forma efectiva. Los dashboards proporcionan una interfaz visual donde se pueden presentar datos en gráficos y tablas, facilitando la interpretación rápida de la información. Las visualizaciones de extremo a extremo (E2E) permiten comprender el flujo completo de datos a través del sistema, mientras que el análisis de causa raíz (RCA) es crucial para identificar la causa subyacente de los problemas. Herramientas de consulta de datos y bases de datos tradicionales junto con data lakes para almacenamiento no estructurado complementan esta sección, ofreciendo un acceso rápido y flexible a la información.
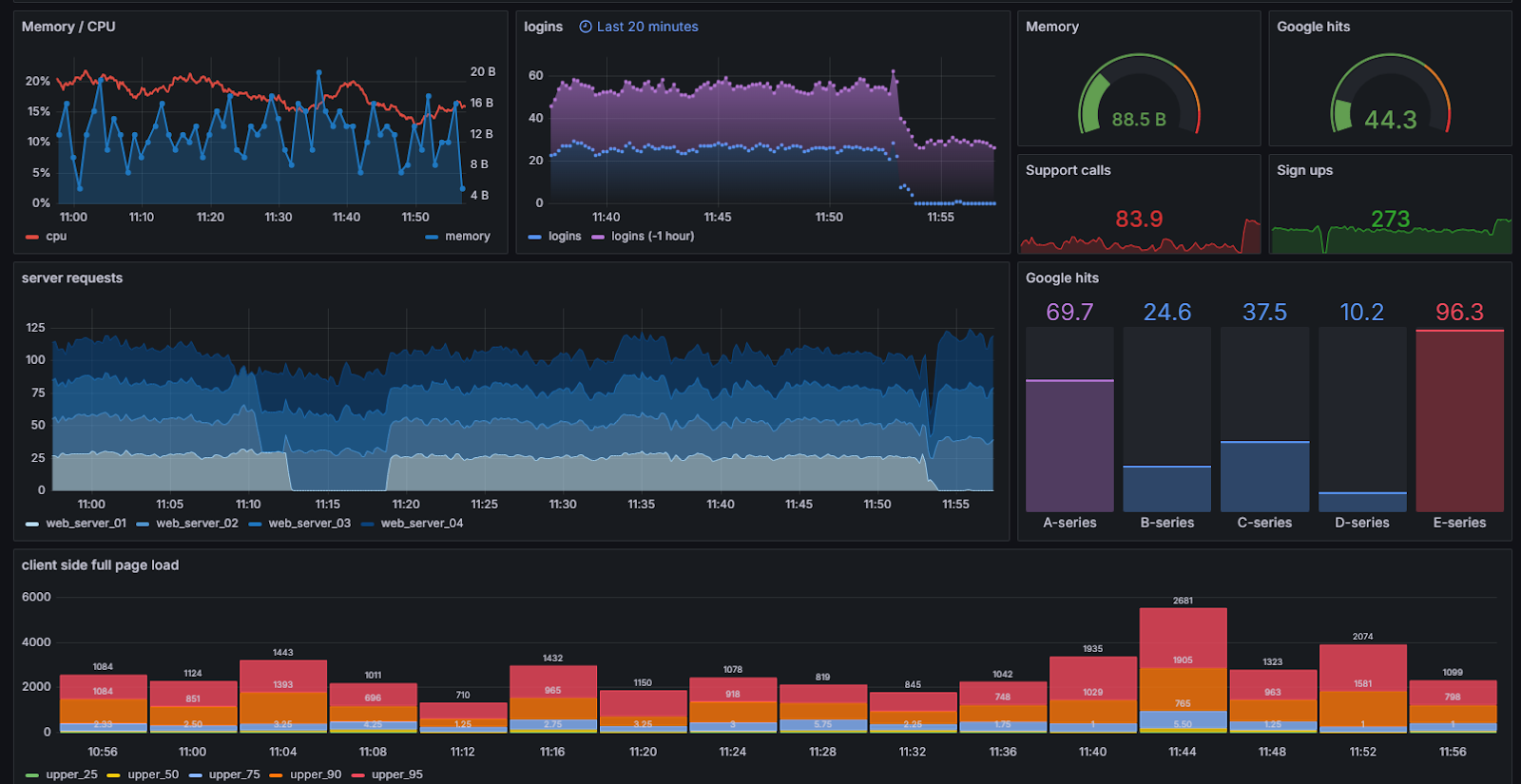
Alertas y Notificaciones
La capacidad de recibir alertas y notificaciones en tiempo real es vital para una respuesta rápida y efectiva ante incidentes. Estas notificaciones se logran mediante integraciones API que permiten la comunicación instantánea entre sistemas, así como notificaciones por correo electrónico que aseguran que los equipos relevantes estén siempre informados.
SLAs
Los acuerdos de nivel de servicio (SLAs) juegan un papel crucial en este proceso, estableciendo métricas y umbrales que aseguran que las alertas sean tanto relevantes como accionables. Estas métricas y umbrales están diseñados para minimizar el ruido y evitar falsas alarmas, permitiendo a los equipos de TI concentrarse en los incidentes más críticos y urgentes.
Recolección y Procesamiento de Datos
La base de la observabilidad radica en la recolección y el procesamiento eficiente de datos. Esto implica varias etapas: el almacenamiento seguro y escalable de los datos recogidos, la normalización para estandarizar los formatos y facilitar su análisis, el filtrado para eliminar el ruido y centrarse en los datos más relevantes, y el enriquecimiento que añade contexto útil a los datos crudos. La correlación de eventos y datos es esencial para descubrir patrones y relaciones ocultas, facilitando una comprensión más profunda de los problemas. Esta capacidad de correlación permite a las organizaciones no solo detectar problemas rápidamente, sino también comprender sus causas raíz, mejorando así la eficacia de las respuestas y las soluciones implementadas.
AIOps
La inteligencia artificial para operaciones de TI (AIOps) representa la próxima frontera en la gestión de operaciones tecnológicas. Aplicando algoritmos avanzados y técnicas de aprendizaje automático, AIOps mejora las operaciones mediante el análisis continuo de datos y la automatización de respuestas. Esto permite una gestión proactiva y predictiva, reduciendo significativamente el tiempo de inactividad y mejorando la eficiencia operativa.
El uso de aprendizaje automático para la detección de anomalías permite identificar problemas antes de que afecten al usuario final. Algoritmos de Machine Learning (ML) supervisados y no supervisados son capaces de aprender patrones normales de comportamiento en los sistemas y detectar desviaciones que podrían indicar fallos o vulnerabilidades inminentes. Estos algoritmos pueden analizar grandes volúmenes de datos en tiempo real, identificando comportamientos anómalos como picos inusuales en el tráfico de red, errores frecuentes en aplicaciones o degradación en el rendimiento del sistema. La detección de anomalías basada en aprendizaje automático no solo alerta a los equipos de TI sobre problemas potenciales, sino que también puede desencadenar automáticamente acciones correctivas, como el reequilibrio de cargas de trabajo o la aplicación de parches de seguridad.
El procesamiento del lenguaje natural (NLP) puede analizar logs y alertas, clasificándolos y proporcionando contexto adicional, lo que permite una búsqueda de datos más efectiva y una resolución de problemas más rápida. NLP es especialmente útil para manejar grandes volúmenes de datos no estructurados, como los generados por sistemas de monitoreo y registros de eventos. A través del análisis semántico y la comprensión contextual, NLP puede transformar estos datos en información accionable. Por ejemplo, puede identificar y correlacionar eventos similares, agrupar alertas relacionadas, y sugerir soluciones basadas en incidentes previos.
Además, NLP facilita la interacción entre los sistemas de AIOps y los operadores humanos mediante interfaces conversacionales o chatbots, que pueden responder preguntas, proporcionar informes de estado y ejecutar acciones específicas basadas en comandos de lenguaje natural. Esto no solo mejora la accesibilidad y usabilidad de las herramientas de monitoreo y gestión, sino que también permite a los equipos de TI resolver problemas de manera más rápida y eficiente.
En conjunto, el aprendizaje automático y el procesamiento del lenguaje natural en el contexto de AIOps permiten una observabilidad avanzada, donde los sistemas no solo son monitoreados pasivamente, sino que son capaces de aprender, adaptarse y responder de manera autónoma a las condiciones cambiantes y a los desafíos emergentes. La detección de anomalías juega un papel crucial en este proceso, proporcionando una capa adicional de seguridad y resiliencia. Esto lleva a una infraestructura de TI más resiliente, con una capacidad mejorada para mantener la continuidad del negocio y ofrecer experiencias de usuario optimizadas.
Fuentes y Tipos de Datos
En un entorno digitalizado, los datos provienen de diversas fuentes, como servidores on-premise y servicios en la nube. Los tipos de datos recolectados incluyen métricas cuantitativas sobre rendimiento y estado, trazas de transacciones y solicitudes, y logs de eventos y mensajes del sistema. Verificaciones como los TCP checks y HTTP checks aseguran la conectividad y disponibilidad. Además, el monitoreo sintético simula transacciones de usuarios, y el monitoreo de usuarios reales analiza la experiencia real de los usuarios, proporcionando información crítica para la mejora continua.
Análisis y Optimización
Los datos funcionales derivados de la observabilidad son esenciales para realizar análisis detallados del rendimiento del sistema (profiling) y la optimización financiera de los recursos en la nube (FinOps). Estos análisis permiten a las organizaciones optimizar sus operaciones, reduciendo costos y mejorando la eficiencia. El profiling ayuda a identificar cuellos de botella y oportunidades de mejora en el rendimiento, mientras que FinOps se enfoca en maximizar el valor de la inversión en infraestructura en la nube, balanceando el costo y el rendimiento.
Conclusión
La observabilidad se ha convertido en una piedra angular para la gestión de sistemas digitales en el contexto de la transformación digital. Su capacidad para proporcionar una visibilidad integral y en tiempo real del estado y el rendimiento de los sistemas no solo mejora la continuidad operativa y la eficiencia, sino que también facilita una toma de decisiones más informada y estratégica. Al integrar logs, métricas y trazas, y apoyarse en tecnologías avanzadas como el aprendizaje automático y el procesamiento del lenguaje natural, la observabilidad ofrece una perspectiva holística que permite identificar, diagnosticar y resolver problemas de manera proactiva.
La evolución desde la monitorización tradicional hacia la observabilidad ha ampliado significativamente las capacidades de las organizaciones para gestionar infraestructuras complejas y distribuidas, mejorando no solo la resiliencia y la seguridad, sino también la experiencia del usuario final. Los stacks modernos de observabilidad, con sus herramientas avanzadas de dashboarding, alertas, recolección y procesamiento de datos, y AIOps, representan un avance crucial en la gestión de operaciones tecnológicas, asegurando que las organizaciones puedan adaptarse y prosperar en un entorno digital dinámico y competitivo.
En última instancia, la implementación de prácticas de observabilidad permite a las empresas no solo reaccionar ante incidentes, sino anticiparse a ellos, optimizando recursos, reduciendo costos y fomentando una cultura de mejora continua e innovación. La observabilidad no es solo una herramienta técnica; es un facilitador estratégico esencial para cualquier organización que busque mantener su relevancia y competitividad en el mercado actual.





