 Read Review
Read Review

Introducción
Uno de los campos en el que se pudo observar una clara evolución en los últimos años es en la provisión masiva, comprensión y evaluación de la información de los cuales surtieron términos como BigData o Machine Learning que actualmente ya hacen parte de nuestro día a día y que son clave en la caza de carencias, mejoras y soluciones que puede necesitar cualquier servicio que, en general, busca la mejor experiencia para su objetivo final.
TSDB & Stacks
Base de datos de series temporales
A raíz de esta exuberante necesidad de almacenamiento de valiosos datos cuyo principio básico es la recolecta de cualquier suceso o evento (métrica) que tenga cabida en un punto del tiempo y se pueda registrar por la captación previa de cualquier dispositivo digital, empezaron a aparecer perfeccionados sistemas de almacenamiento o bases de datos orientadas a series de tiempo o TSDB (del inglés Time Series DataBase).
Aunque no sean un invento nuevo, las primeras bases de datos de este tipo estaban sobre todo orientadas y limitadas a sectores financieros. Coincidiendo con la informatización actual a todos los sectores económicos, se crearon nuevos Stacks (paquetes de soluciones) tecnológicos completos que facilitan y estandarizan la implementación de dichos procesos BigData.
Partes de un stack
Estos stacks suelen componerse como mínimo de los siguientes elementos (de abajo hacia arriba):
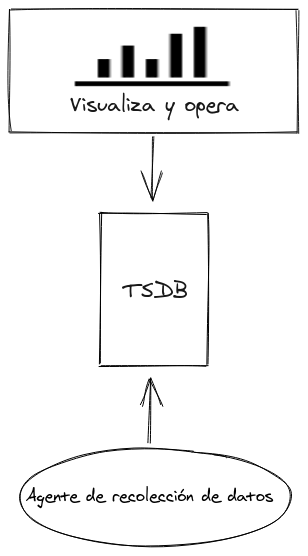
- Agente de recolección: Es un componente que lleva integrado múltiples mecanismos para comprobar distintos servicios como métricas del sistema operativo (discos, memoria, CPUs, …) consumir APIs remotas, aplicaciones (Nginx, contenedores Docker, …), logs, etc. aunque se puede programar cualquiera necesidad de manera adicional.
Dichos agentes suelen seguir el siguiente flujo (denominado ETL; Extract Transform, Load) todo ello configurable para lograr una salida a la base de datos coherente a las necesidades:
Entrada de datos ⇒ Procesado de datos ⇒ Salida de datos a la TSDB
– Cabe destacar que el uso del agente es opcional y que se puede optar por otros métodos para alimentar la TSDB como por ejemplo utilizar directamente la propia API.
– Algunos agentes de extracción de determinados stacks tienen compatibilidad con otras TSDB. - TSDB: Es el componente central donde se almacena con marca de tiempo todas las métricas recibidas y al que se debe de prestar especial atención a la hora de elegir la opción más adecuada a las necesidades. Están optimizadas para soportar gran cantidad de datos entrantes de manera simultánea y las almacena de una manera lógica dependiendo del producto.
El hecho de que tenga que aguantar tanta carga supone todo un reto. Imaginando un escenario con un dispositivo, con una frecuencia de muestreo de 15 métricas por segundo con una carga útil de 1KB, puede generar 43MB de datos cada día, lo que significa que 100 sensores crearían una carga de datos de 4GB por día y es por ello que es necesario realizar un análisis previo de necesidades a fin de aprovisionar los recursos y elegir la TSDB más adecuada.
Dichas bases de datos cuentan con un lenguaje de consulta propio ya sea un derivado de SQL, o cualquier propio lenguaje DSL. - Parte de visualización: Es la parte que permite visualizar y consultar los datos mediante un entorno gráfico, elaborar cuadros de mando, etc.
No quiero detallar mucho esta parte a debido que en muchos casos se decide reemplazar o complementar con otro software como puede ser Grafana.

Ejemplo de dashboard de Grafana
ELK vs TICK (Elasticsearch vs InfluxDB)
Actualmente existen 2 stacks en cabeza de fila, que a priori podrían servir para el mismo propósito pero como ya sabemos, a la hora de obtener la solución más óptima las diferencias son muchas.
ELK Stack

Está basado en Apache Lucene, un motor de búsqueda open source, su punto fuerte es la indexación, análisis y recuperación de contenido almacenando “documentos textuales” en índices definidos por el usuario. Cada documento va asociado un timestamp (marca de tiempo). Tiene incorporado funcionalidades de Machine Learning facilitando la búsqueda de patrones en los datos para realizar previsiones de sucesos y detección de anomalías sin herramientas externas. Sus aplicaciones más frecuentes son como motor de búsqueda, monitorización de aplicaciones o de un sistema, análisis de tendencias y negocios. Sus componentes integrados son los siguientes:
- Beats y Logstash como parte de extracción; Logstash es un componente centrado en la extracción de logs de distintos servicios y los Beats son complementos principalmente desarrollados por la comunidad para cubrir el resto de necesidades o servicios.
- Elasticsearch como componente core de y base de datos TSDB; una de sus ventajas es de ser distribuida por lo que puede crecer horizontalmente agregando nodos al cluster y extendiendo su capacidad. Tiene varios mecanismos de consulta e ingesta de información y cuenta con su propio DSL.
- Kibana como parte de visualización por una parte y de administración del stack por otra. Permite visualizar la información y viene integrado con cuadros de mando predefinidos para ciertos servicios.
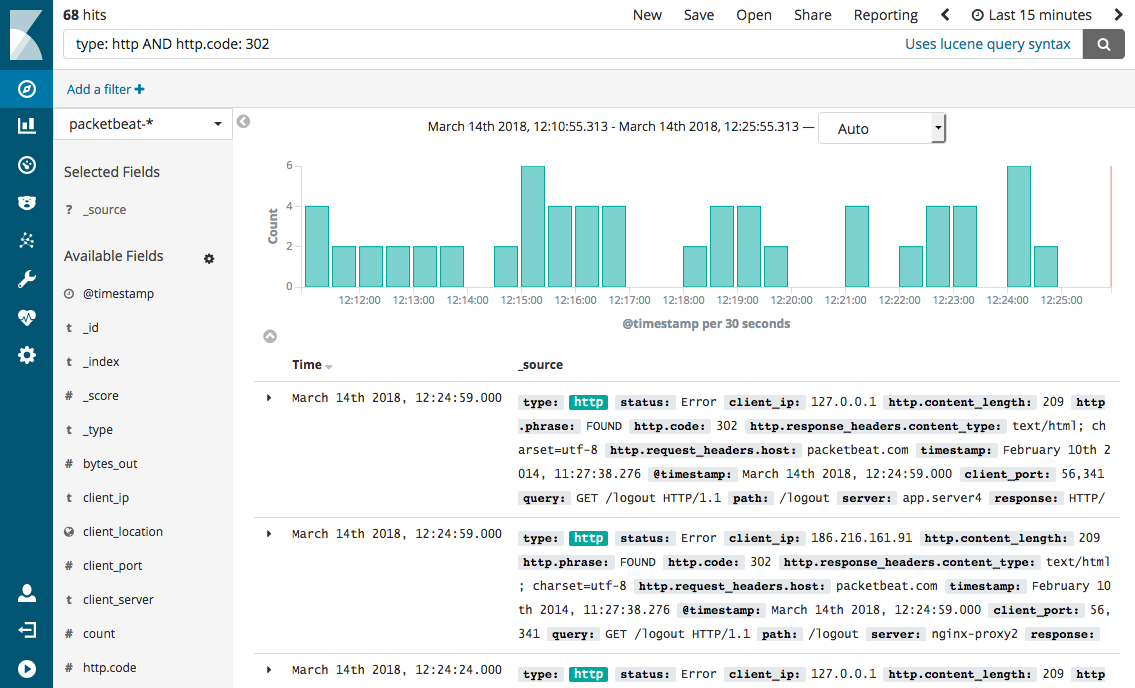
Ejemplo de caso de uso
Aunque sea de manera transparente, estamos utilizando los servicios de Elasticsearch en numerosas ocasiones al utilizar ciertas aplicaciones. Un ejemplo de ello es la conocida aplicación de Uber; el stack ELK es su componente principal y se utiliza tanto para las búsquedas de conductores en base a la cercanía y el cálculo de la tarifa dinámica en base a la demanda, zona, ubicación del conductor y demás factores.
TICK Stack
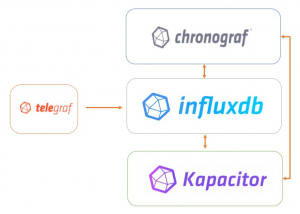 De aparición más reciente, Influxdata presenta su stack TICK para ofrecer una completa plataforma destinada al almacenamiento de métricas, comúnmente utilizado en la recopilación de datos de sensores IoT aunque se puede utilizar para almacenar y procesar información de cualquier fuente. También se puede utilizar como una plataforma de monitorización de sistemas muy completa puesto que cuenta con componentes integrados con funcionalidades muy específicas. Está escrito en Go por lo que en general tiene un excelente rendimiento a la hora de almacenar datos que llegan masivamente. Se pueden conectar otros elementos externos como por ejemplo LoudML para realizar la parte de Machine Learning. Sus componentes integrados son los siguientes:
De aparición más reciente, Influxdata presenta su stack TICK para ofrecer una completa plataforma destinada al almacenamiento de métricas, comúnmente utilizado en la recopilación de datos de sensores IoT aunque se puede utilizar para almacenar y procesar información de cualquier fuente. También se puede utilizar como una plataforma de monitorización de sistemas muy completa puesto que cuenta con componentes integrados con funcionalidades muy específicas. Está escrito en Go por lo que en general tiene un excelente rendimiento a la hora de almacenar datos que llegan masivamente. Se pueden conectar otros elementos externos como por ejemplo LoudML para realizar la parte de Machine Learning. Sus componentes integrados son los siguientes:
- Telegraf es el agente que realiza la extracción de datos. Tiene integrado cerca de 180 plugins de entrada para distintas fuentes y otros muchos para postprocesamiento sin necesidad de instalar ninguna dependencia adicional. Es muy versátil a nivel de configuración y en general consume pocos recursos. Envía los datos a InfluxDB.
- InfluxDB es la base de datos central, también puede ser distribuida. Utiliza un lenguaje de consulta derivado de SQL, InfluxSQL. Los datos se ordenan por fragmentos y cada fragmento pertenece a un único grupo de fragmentos; esta ordenación lógica permite un enfoque altamente escalable para aumentar el rendimiento. Ofrece políticas de retención para establecer caducidad en las métricas para así liberar espacio, y más características que la hacen muy eficiente.
- Kapacitor es un motor que permite crear flujos de alertado en base a las métricas, permitiendo al usuario establecer reglas.
- Chronograf como parte de visualización, permite crear los grafos e interactuar con el resto de elementos del stack.
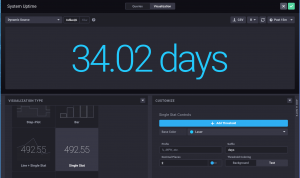
Ejemplo de caso de uso
PayPal necesitaba encontrar una solución escalable de monitoreo de host de extremo a extremo para reemplazar la anterior, a medida que la empresa modernizaba su infraestructura y hacía la transición de muchas de sus aplicaciones a una arquitectura basada en contenedores. Actualmente, siguen utilizando influxDB como principal elemento en su monitorización.
Conclusiones
Ambos stacks son muy potentes y pueden ofrecer una funcionalidad muy similar; sus puntos fuertes se pueden combinar para lograr una solución de monitorización y análisis muy completa.
Sin embargo y desde mi punto de vista, se debería de reservar el uso de ELK para el almacenamiento, análisis y búsqueda de datos textuales y el uso del stack TICK para el almacenamiento, monitorización y alertado en base a las métricas del conjunto de nuestro sistema.




