Read Review
Read Review

Introduction
Welcome to a new article, where we will explore the exciting updates to Chia DataLayer .
Today, we're going to dive into the newly released plugin integration, a hot and recent innovation from the Chia development team.
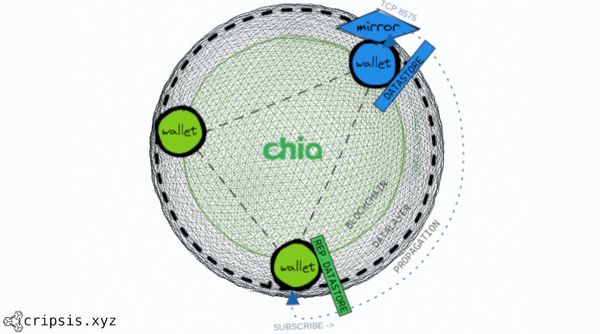
As it has been made known very recently, Chia has released a new functionality that allows the development of an additional logical layer to DataLayer that allows the development of plugins in Python in order to synchronize data between Chia DL and other more traditional data sources to facilitate the strengthening and availability of said data, or to give it the use that the user deems necessary.
The first plugin developed by the Chia team allows us to use Amazon S3 as additional storage for our DataLayer datastores.
This synergy between the cloud and DL is highly beneficial in terms of operational efficiency and cost reduction as it is possible to adjust cloud resources according to demand without having to invest in expensive physical infrastructure.
Amazon S3
The first plugin developed by Chia's Core Team is an integration with Amazon S3 buckets, which allows us to work with data between both technologies in both a push and pull model, that is, we can use an S3 bucket to download data to DL or use it on the contrary to upload data from DL to S3.
This allows us to easily have a managed replica of our Datalayer repository, with all the advantages that having it in a cloud offers us.
Data structure of an S3 bucket
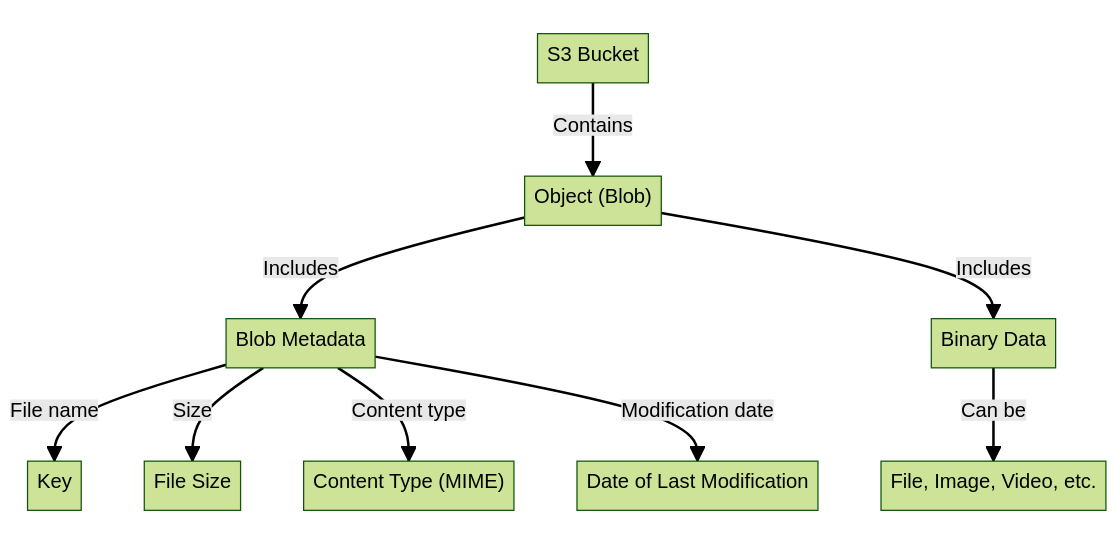
The diagram illustrates the structure and components of an object stored in an Amazon S3 bucket. Parts of the diagram:
- S3 Bucket – At the top of the diagram, we have the S3 Bucket. A bucket is like a container in Amazon S3 where data is stored in the form of objects. Buckets are useful for organizing storage and controlling access to data.
- Object (Blob) : Inside the bucket, we find an Object, also known as a Blob. Objects are the fundamental units of storage in Amazon S3. Each object consists of data and a set of metadata that describes the object.
- Blob metadata : Metadata is associated with the object and is a set of additional information about the object. Metadata includes:
- Key : The key is the file name of the object and is unique for each object within a bucket. It is used to access the object in Amazon S3.
- File Size : The metadata includes information about the file size of the object.
- Content Type (MIME) : The metadata also contains the content type of the object, which specifies the format of the data.
- Last Modified Date : The metadata contains the date the object was last modified.
- Data in Binary : The data of the object is stored in binary format. The data can be any type of content.
Chia DataLayer
Data structure of a Chia DataLayer datastore
The diagram provides a schematic view of how a Datastore works within the Chia DataLayer, here are the components presented in the diagram:
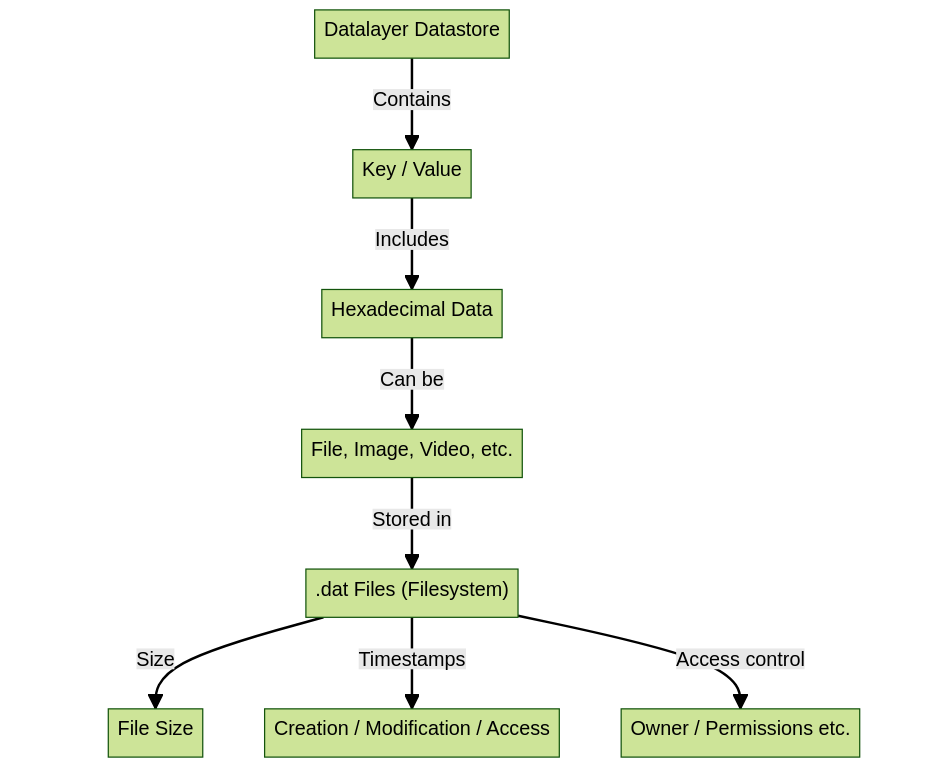
- DataLayer Datastore : At the top of the diagram is the DataLayer Datastore. A Datastore acts as a repository to store information in the form of key and value pairs.
- Key/Value : Within the Datastore, data is stored as key and value pairs. Each stored item has a unique key that is used to access and retrieve the associated value.

- Data in Hexadecimal : The stored values are in hexadecimal format. This means that the data is represented using a base 16 numbering system that includes the numbers 0 through 9 and the letters A through F.
- File, Image, Video, etc .: Data in hexadecimal can represent various types of content, such as files, images, videos, and more.
- Files .dat (Filesystem) : The content, such as files, images, videos, etc., is stored in files with a .dat extension within the file system. .dat files are binary data containers and are used to store information.
Common things
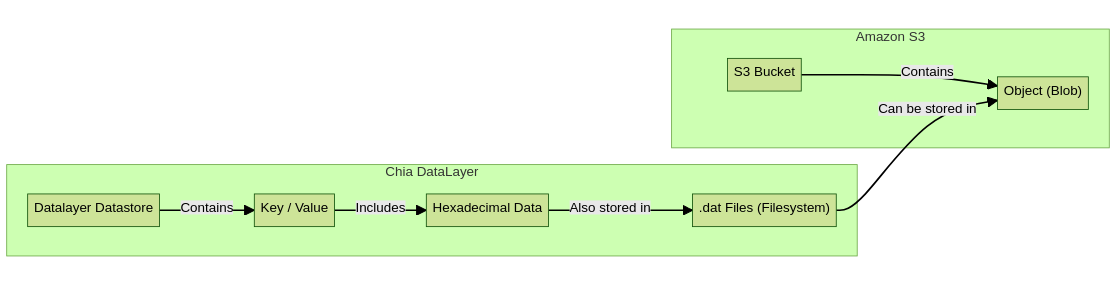
- Data Containers : Both Amazon S3 and Chia DataLayer act as containers to store data. Amazon S3 uses "Buckets" while Chia DataLayer uses "Datastores".
- Storage Structure : In both systems, data is stored in a structured way. Amazon S3 stores data in the form of "Objects (Blobs)", while Chia DataLayer stores data in pairs of "Key / Value" although they finally end up in .DAT files at the filesystem level, this suggests that both systems allow organizing and storing data in a structured way.
- The .DAT files are the ones that will be stored within the S3 blobs.
Requirements to use Amazon S3 as a replica of a DataLayer repository
- Create/reuse an AWS IAM user
- Provide you with the level of permissions necessary to be able to interact with S3 buckets
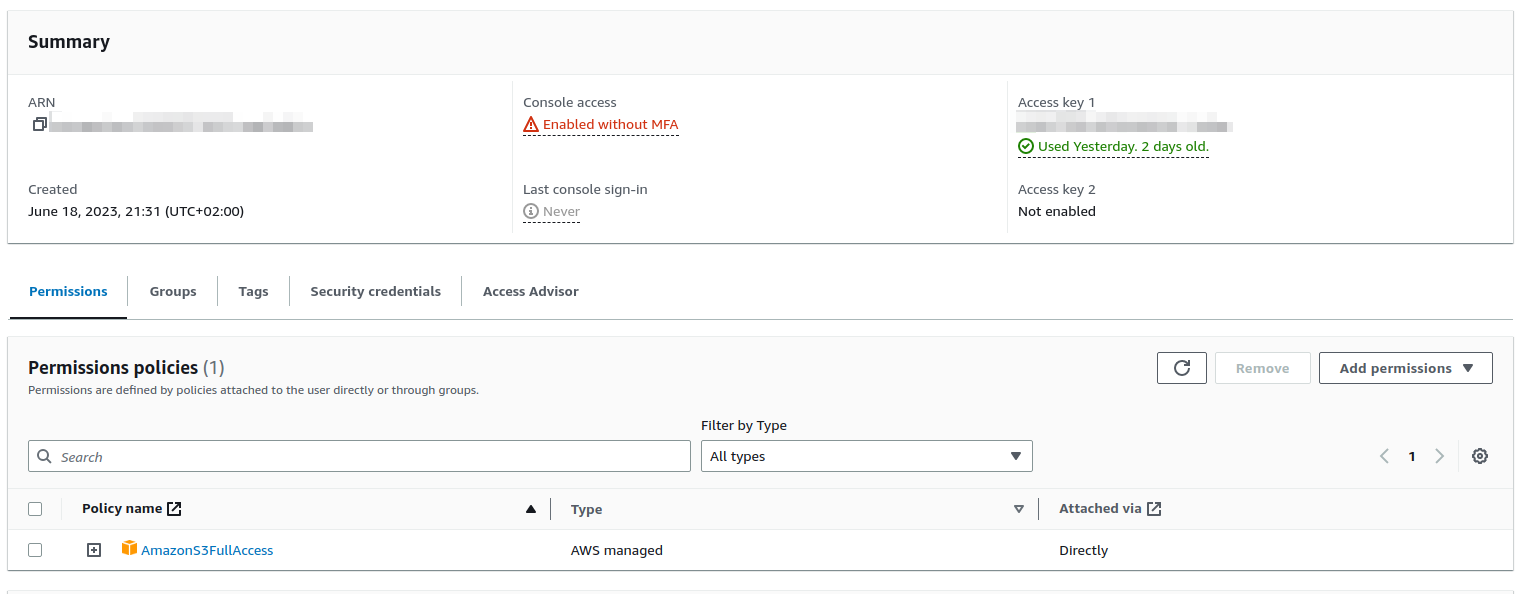
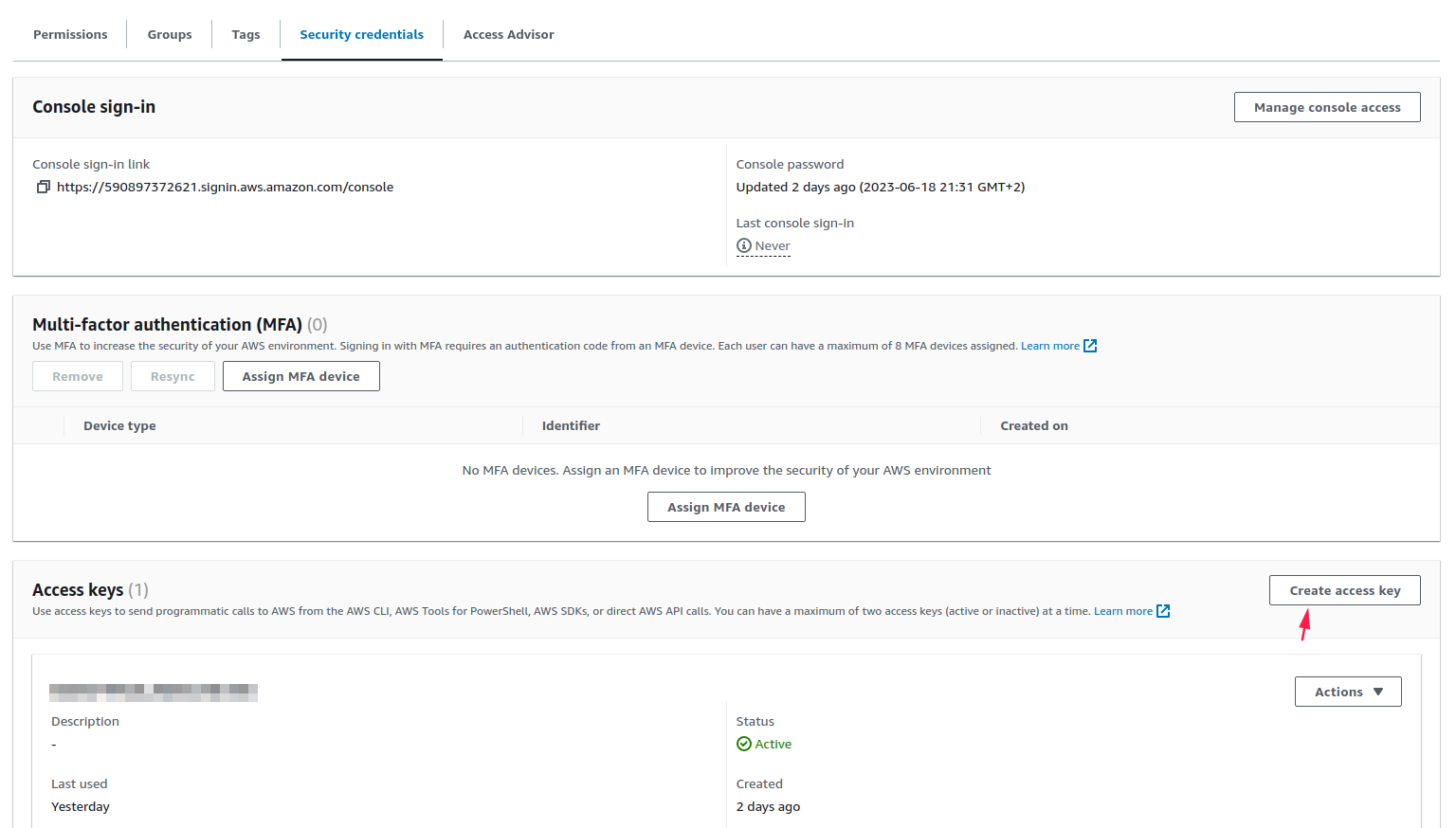
3. Create an Access Key and write down the tokens to be able to use them later when configuring the plugin
4. Go to the Amazon S3 interface and create an empty Bucket (in my case I named it test-datalayer)

Identify dependencies
- Go to the directory. /chia/data_layer from an official chia-blockchain installation .
- Locate the following files:
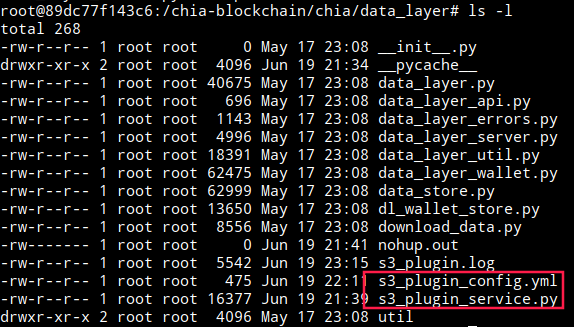
3. s3_plugin_config.yml : It is the configuration file where the parameters to configure the plugin are indicated, as well as the secrets to authenticate with Amazon S3.
4. s3_plugin_service.py : It is the plugin script that interacts with S3 and DataLayer, reading the data from the s3_plugin_config.yml configuration file.
Prepare the configuration
Edit the s3_plugin_config.yml file and adapt it as needed. The following example will be used to upload files from an existing DL datastore to the previously created Amazon S3 bucket.

# This is the beginning of a block called "instance-1", which groups specific configuration for an instance.
instance-1:
# Defines the file name where the logs will be saved.
log_filename: "s3_plugin.log"
# Defines the logging level.
log_level: DEBUG
# Specifies the file system path where the server DAT files will be located.
server_files_location: "/root/.chia/mainnet/data_layer/db/server_files_location_mainnet"
# Defines the port on which the service or application will run.
port: 8998
# Credentials with privileges to access the AWS S3 service.
aws_credentials:
# Access key ID to authenticate with AWS.
access_key_id: "xxxxxxxxx"
# Secret access key to authenticate with AWS.
secret_access_key: "xxxxxxxxxxx"
# AWS region to connect to.
region: "eu-west-3"
# Block containing the configuration to work with a DataLayer datastore.
# If a value is provided for upload_bucket, the .DAT files from the datastore specified below in store_id will be uploaded to that bucket.
# If an S3 bucket is provided in download_urls, it will download files from one of those sources. It must contain the s3 schema. Example:
# download_urls: ["s3://cripsis-xyz-1", "s3://cripsis-xyz-2"]
# This is an item in a list. It can contain various elements.
# Unique identifier of the storage.
stores:
- store_id: "c789a1dfe9cf9b5e1650cabd2b3eb96451806bc0961a0e9e3611ac9bf9909f58"
# Specifies the name of the AWS S3 bucket to which files will be uploaded.
upload_bucket: "test-datalayer"
# A list of URLs from where files can be downloaded. It is empty in this example.
download_urls: []Boot the instance
We proceed to start the instance-1 instance that we have defined within our configuration file with the following command:
python3 s3_plugin_service.py instance-1As we can see, the instance identifier must be specified as the first parameter of the script

Now that we know that it has been started and without errors, we proceed to run it in the background with nohup:

nohup python3 s3_plugin_service.py instance-1 &start the climb
- Based on the Chia Rest API, we can start uploading the files with the following HTTP request with curl:
curl -X POST -d '{"store_id": "c789a1dfe9cf9b5e1650cabd2b3eb96451806bc0961a0e9e3611ac9bf9909f58"}' http://127.0.0.1:8998/handle_upload- Modify store_id with the ID of the desired datastore.

- Verify that the answer is true.
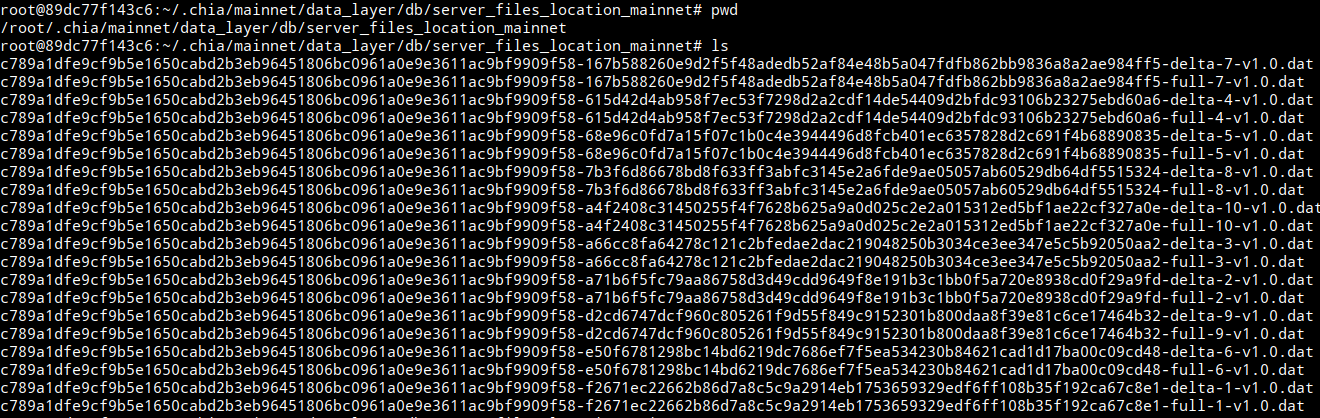
curl -X POST http://127.0.0.1:8998/add_missing_files -H 'Content-Type: application/json' -d '{"store_id": "c789a1dfe9cf9b5e1650cabd2b3eb96451806bc0961a0e9e3611ac9bf9909f58", "files": "[\"c789a1dfe9cf9b5e1650cabd2b3eb96451806bc0961a0e9e3611ac9bf9909f58-167b588260e9d2f5f48adedb52af84e48b5a047fdfb862bb9836a8a2ae984ff5-delta-7-v1.0.dat\", \"etc.dat\"]"}'The new files that are generated should be uploaded after re-executing the command handle_uploadseen above.
Verify data in S3
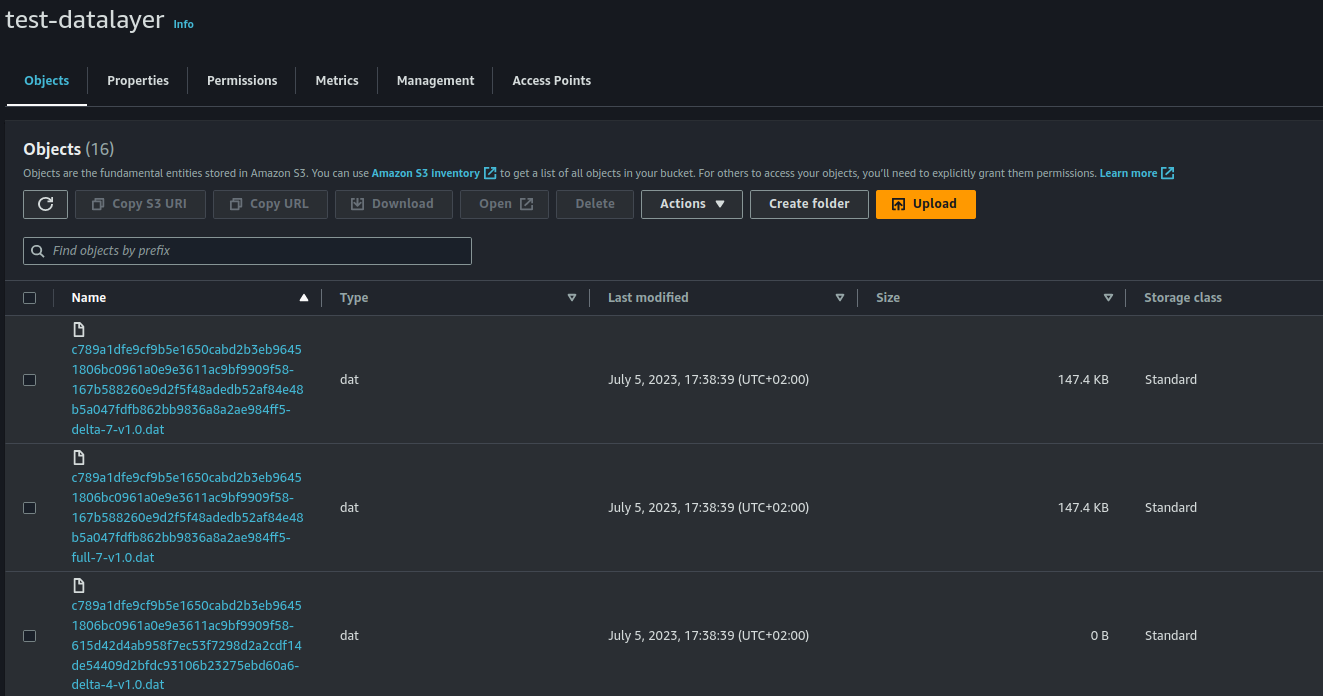
We can see that the data has already been uploaded correctly!
Creating and sharing quality content takes time and effort. If you appreciate my work and would like to see more of it, please consider making a small donation.
Every contribution, however small, makes a big difference and helps me continue this work that I enjoy so much.
If you have any kind of suggestion or would like me to talk about a specific topic, let me know!